On July 21, 1969, with the usual fanfare accorded to conquering heroes, the Apollo 11 astronauts returned to earth, leaving behind a plastic American flag, which stood unwaving in the airless desolation of the lunar terrain. With them they brought 58 pounds of moon rocks, which after being held in quarantine to guard against microscopic invaders, were turned over to geologists eager to apply their knowledge of the earth to the study of a nearby world. The results of their experiments were reported several months later at the First Annual Lunar Science Conference, then encoded and stored in a computer, where they were of instantaneous use to anyone familiar with the arcana and incantations needed to retrieve information from a data base. To benefit from NASA’s largesse, a geologist would have to think like a computer and speak its language instead of his own.
NASA officials believed there must be a better way. So, in the summer of 1970, they approached William A. Woods, a young computer scientist who was making a name for himself as a pioneer in the art of designing programs that could understand English. Recently, Woods had written two landmark papers suggesting ways to program a computer with not only the rules of syntax, by which proper sentences are formed, but also a sense of semantics, a feel for what they mean.

Today Woods, like many of his colleagues in artificial intelligence, has gravitated toward the side of the field concerned with designing and selling expert systems. As chief scientist at a Cambridge, Massachusetts, company called Applied Expert Systems, he is in charge of the research and development of decision-making programs for the financial services community, a potentially lucrative market that includes banks, brokerage firms, insurance companies, and accounting firms.
“My role here,” as he wrote in a letter to his colleagues shortly after joining the company in 1983, “is to keep APEX properly positioned on the technology curve–at or near the frontier but not beyond the point of feasibility.…Principally,” he continued, “I will be interested in knowledge representation, automated reasoning, natural language input and output, computer assisted instruction, and foundations of meaning and understanding.”
The foundations of meaning and understanding. It would be difficult to name an area of research more fundamental to appreciating what it means to be human. What is the meaning of meaning? Philosophers call this the problem of semantics, and it seems like a subject that would be at home in the halls of an Ivy League university or on the greens of Oxford than in a computer software company.
To those familiar with his accomplishments, the letter was vintage Woods. Throughout his career his work has illustrated the combination of philosophy and engineering that characterizes AI. Designing software that understands English, or performs any activity we’d deem intelligent, causes researchers to address problems basic to the foundations of philosophy, psychology, linguistics, logic, and mathematics, as well as computer science. On the other hand, there is an overriding desire to test ideas by making systems that work.
“AI is the eclectic discipline,” Woods said, “sitting where all those fields must interface.” Interface, he says. Not “meet,” “come together,” “overlap,” or “coincide.” Like many people whose research has led them to think of the world in terms of systems, his conversations are sprinkled with technical terms. He talks of “push-down stacks,” “tree structures,” and “linear bounded automata,” as though those were terms we all should understand. When it comes to dealing with things philosophical, he believes that he and his colleagues in AI just might have an edge over their technologically less sophisticated predecessors.
“Philosophers didn’t have the image of the computer in which to embody their ideas,” he explained. “What I’m trying to do the philosophers never have done. I’m trying to solve the problem of meaning instead of just contemplating and savoring it.
“On the other hand,” he concedes, “people in AI have a tendency to plow ahead with a supposed solution before they understand what the problem is.”
One needs useful systems, but without good theory the work is built on sand (or, perhaps more appropriately, silicon). Practical applications are important, he likes to say, but they must be philosophically adequate.
Fifteen years ago, when NASA approached Woods for what now would be called a “natural language front end to a data base” they were interested less in philosophical questions than in finding a solution to a frustrating problem.
“They came to me,” Woods recalls, “and said, ‘We’ve got this data base that has all the chemical analyses of the first year’s work on the Apollo moon rocks, and we’d like to make them available to all the geologists out there. The problem is that we’ve formalized the data base–we have all the units rationalized and the contents are proper and so forth–but if somebody wants a question asked it still takes a Fortran programmer to understand what the question is and to know the formats of the data tables and what the names of the fields are–all those details. Then he can write a little program that will go get the answer to the question.”
Specifically, NASA had a computerized table with 13,000 columns, each representing a sample of lunar soil. The rows of the table showed the concentrations of various chemicals in each sample, and told how old it was. Also included in the table were bibliographic references to the scientific articles from which the information had been collected. If a geologist wanted to ask something like, “What is the average concentration of aluminum in high alkali rocks?” he would have to write a program that would find all the alkalis, which were known to the computer as “Type A’s,” look up the concentration of aluminum (encrypted as AL203), and average the results. To ask other questions he would have to know other codes: olivine is OLIV, breccias “Type C’s.” Every mineral had an abbreviation–ilmenite, chromite, silicon, magnetite, apatite, titanium, strontium, potassium, rubidium, iridium. Remembering them all was tedious enough but not nearly so much as programming in the rigid and unforgiving format of Fortran.
“What we’d like,” the NASA officials told Woods, “is to enable the geologist to just ‘dial up’ and communicate in English the same kind of thing he’d say to his colleagues, and get the answers out from that.” The computer, they believed should be responsible for translating from English to computerese.
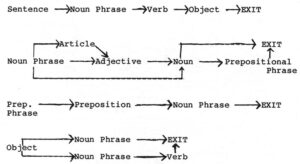
When NASA approached Woods he was working at Bolt Beranek and Newman, a research firm in Cambridge, that was developing one of the best private artificial intelligence laboratories in the country. He had joined BBN after leaving Harvard University’s Aiken Computation Laboratory, where he had become intrigued by the notion that a grammar, a set of rules for combining words into sentences, could be thought of as a machine whose output was language. Or, conversely, a sentence could be fed to a grammar machine that would parse it: dissecting it into subject and object, nouns, verbs, adjectives, adverbs, prepositions, et cetera, producing a chart similar to those of high school English students ordered by their teacher to diagram a sentence. Once a sentence was cast in this form, it would be ready for another program (yet to be invented) that would decipher its meaning.
At the time Woods began studying at Harvard, in the mid 1960s, a typical parser might recognize a sentence like, “The dogs ran down the street,” as grammatical, but it might also accept such atrocities as, “The dog run down the street.” Such a parser knew that a sentence can consist of a noun phrase followed by a verb phrase, and that a noun can consist of an article (“a,” “an,” or “the”) followed by a noun (with possibly one or more adjectives in between), and that a verb phrase can consist of a verb followed by a prepositional phrase, which consists of a preposition followed by a noun phrase–but it might not know that the subject and verb both had to be either singular or plural. Such problems could be resolved by adding more rules to the grammar, but only at the expense of making the system unwieldy and inefficient. When Woods arrived at Harvard there were in existence computerized grammars that contained thousands of rules, and still they were both too inconclusive, accepting sentences that weren’t English, and too exclusive, failing to recognize ones that were. By the time some of the more complex grammars had finished processing a simple sentence–applying rule after rule in every conceivable combination–an hour might have passed.
Woods’ solution to this problem was to invent a parsing algorithm, called an Augmented Transition Network, that could handle the complexities of English, or at least a large number of them, and still run efficiently, parsing a sentence not in an hour but a minute, and, in the systems used today, in less than a second.
The system was called a transition network because it consisted of a grammar that was structured like a maze. Consider the sentence, “He watched the gasoline can explode,” which can be parsed with a network like the one in Figure 1. The process is a little like playing a game of Dungeons and Dragons. We start at the beginning of the top-most pathway, which tells us that, according to the simplified grammar of our network, a sentence must begin with a noun phrase. To see what a noun phrase is, we drop down to the Noun Phrase network and take the top branch, encountering an article followed by an adjective. “He” is not an article, so we return to the beginning and try another path. The middle road leads us to an Adjective. “He” is not an adjective either, so we try the last possibility, the bottom path that leads directly to a node called Noun. “He” is a noun, so we’ve found a way out of the first chamber of the maze.
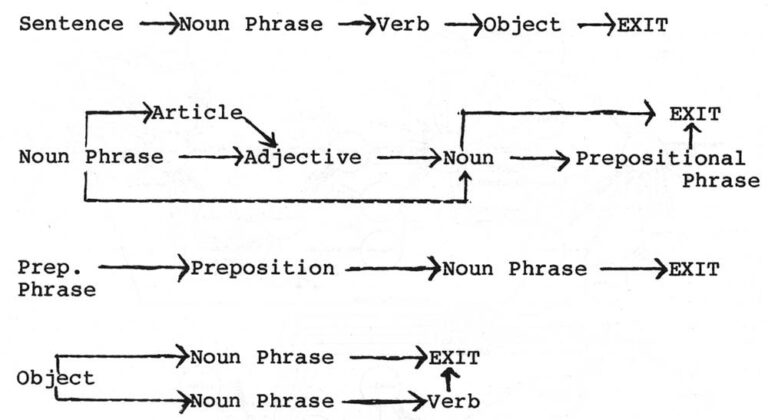
Now we are faced with two paths. The middle one leads to a Prepositional Phrase. Since the next word in the sentence is not a preposition we take the top path, exiting from the noun phrase network and returning to the main path above.
Continuing in this manner, backtracking when we hit dead ends, we weave our way through the labyrinth. If we can find our way to the other end, the sentence is parsed. If not, it’s grammatical.
When Woods was beginning to work on the language problem, transition net grammars were not new. But the one Woods invented was augmented with new, more powerful features: as it followed a sentence through a maze, it could make tentative decisions, changing or confirming them depending on what it found later in its exploration. It also had the ability to remember what it discovered as it moved along that a verb is singular or plural, that the verb seemed to be in the active or the passive voice. Then it could use that information to help with decisions further down the line. Another way to think of the difference is this: a regular transition network operates as though the maze were being negotiated by a lobotomized mouse, who can only see what’s in front of it and can’t remember where it’s been. When it hits a dead end it must back up and try another route. An augmented transition network can take more of a birds-eye view. It can see a bigger part of the picture, take more factors into account.
The diagrams of ATNs powerful enough to parse most or even many English sentences fill charts the size of walls. They are as dense with nodes and connections as the writing inside a computer cabinet, a visual demonstration of how complex language is. Phrases can be embedded in phrases, many levels deep: “the blue house sitting at the edge of the large forest where the twisting river meets the ever changing sea…” ATN grammars were the first to be able to handle richness and subtlety.
ATNs did have some problems. For one thing, they were almost too syntactic. They would reject even slightly ungrammatical sentences that a human would easily understand. And they would accept grammatical sentences that were nonsense, such as “The gasoline can watched Mary explode.” The ATN didn’t know the meaning of the sentences is parsed.
It would make a good story to say that, having suggested a solution to the syntax problem, Woods went on to tackle semantics. Actually it happened the other way around. Woods invented the ATN while he was an assistant professor at Harvard, a position he ascended to after writing his doctoral dissertation on semantics.
“I attacked the problem,” Woods recalled, “from the point of view of trying [first] to understand what meaning is and [then] how you could get some version of meaning for a computer. That became my thesis topic, and I came up with a model which I call procedural semantics. That model has evolved over the years to become, at this point, something you could think of as a candidate at the level of philosophy for what kinds of things could play the role in the mental life of a machine–or a person for that matter–that seems to be played by what laymen call meaning…That’s not to say it answers all the questions, but it doesn’t seem to have any more holes than any of the other things philosophers have proposed, and considerably fewer than a lot.”
Like grammar, meaning, Woods believed, could be described as a process. Understanding a sentence meant having a procedure that would determine whether it was true or false.
For his thesis Woods used the data base called the Official Airline Guide, which listed flights in North America. It included information on destinations and origins, departure and arrival times, flight numbers, destination and arrival airports, classes of service, and meal categories, etc. “Now if you take a question like, ‘Does American have a flight that goes from Boston to Chicago before 9 o’clock a.m. on Monday?’ I would identify the meaning of that question with a procedure that knew how to compute on that data base whether it was true or not. Now that procedure is in fact composed out of bits and pieces of smaller ones.…”
Guided by a set of rules and a dictionary, Woods’ system would take a parsed version of a sentence and recast it into a simple vocabulary that a computer easily could be programmed to understand. In this particular dialect of computerese, the symbol FLIGHT(X1) meant that X1 is the name of a flight. PLACE(X2) meant that X2 is the name of a place. DEPART (X1,X2) meant that flight X1 departs from place X2. “How many stops does AA-57 make between Boston and Chicago?” looked like this:
LIST (NUMSTOPS (AA-5 7,Boston,Chicago)
The program’s world consisted of a network of several dozen of these basic units of meaning, or “semantic primitives,” which also included AIRLINE, ARRIVE, CONNECT, CITY, DAY, and TIME. Each of them worked as a subprogram that could be automatically combined with others into a procedure that, in the case of Woods’ example, would find all of the flights that went from Boston to Chicago, then rule out the ones that weren’t run by American Airlines, didn’t leave Monday, and that left after 9 a.m. If there were any flights left, then the answer to the question was yes.
In a similar manner, the system could answer more complex questions, such as: “Does any flight go from Boston to some city from which American has a flight to Denver?”
The world of the Official Airline Guide was extremely limited compared to those we hold in our heads. But Woods believed that for brain and computer the principle of understanding was the same.
“If you believe people are some kind of information processing engine–among other things–and that their reasoning processes are some kind of procedures, then it is plausible that what a person has when you say he understands a meaning of a term is a procedure that he can use to do various things with it….”
As we go through life, we build a data base of information about the world. When someone asks us a question–”What is the capital of Alaska?” or “Is John still in love with that woman he met on the airplane?”–we enact some internal procedure that searches the mazes of memory and constructs an answer.
Woods’ system didn’t know what “flight,” “place,” and “day” meant in the same sense that we do. They were irreducible units, defined in terms of one another–to the system they were the unfissionable atoms of meaning. Still, if he had wanted to make a system that knew that a plane was, for example, a type of machine used for flying through the air, he could have defined it in terms of other primitives, which could be broken into still other primitives. But at some point the process of fragmentation must end. In any system there must always be primitive concepts.
Consider the case of an English dictionary. In this great spiderweb of meaning, semantic primitives are words “whose definition,” Woods wrote, “is immediately circular–that is, the word is defined in terms of words which are themselves defined in terms of the original word.” An example is “same,” which, according to Webster’s New World Dictionary, means “alike in every respect,” or “identical.” Looking up the “alike,” we find: “having the same qualities” and “equal.” The word “identical” is defined as “the very same,” “exactly alike,” or “equal.” And “equal” means of the same quantity, size, number, et cetera.”
Unless we already knew the meaning of one of those words–‘same,’ ‘identical,’ ‘alike,’ or ‘equal’–then the dictionary would be useless. One of them must be a semantic primitive, programmed into our brains by our experience with the world outside.
“People presumably learn their primitive concepts [through] their sense impressions,” Woods wrote, “so that a child learns the meaning of the word ‘same’ or ‘alike’ by correlating the term with instances of two identical objects. In computers, however, this process will not be feasible, at least not until we give the computer eyes and ears and a great deal of progress is made in learning theory…”
We have to provide the computer with what life has denied it, programming in the primitives ourselves.
“In this respect, the computer will always be talking about things which it does not know anything about,” Woods wrote, “just as a person blind from birth may talk about colors without ever having perceived them. The blind person, when told that X is green and that Y is the same color as X, may conclude that Y is green, and it is in this manner that the computer can carry on a conversation about things for which it has no external correlates.”
Woods actually never programmed the question answering system described in his thesis. After all, at the same time he wrote it, he still didn’t have an adequate parser. He had assumed that someone else would come up with one. No one did, so, after joining the Harvard faculty, he invented the ATN. Then, in 1970, he left the university for BBN. For his first major project he tackled the NASA problem by writing Lunar, a program made by combining his parser and semantic interpreter.
“We brought up the first version of the system in six months, which included building a 3,500-word vocabulary–it knew all the chemical elements and all the isotopes and all the minerals, every word from several technical articles in lunar geology, and a thousand or so words of basic English that everybody shares. So we put all that in and beefed up the grammar to handle more and more of English and some of the somewhat unusual constructions which showed up in that domain, and built up the semantic interpretation rules for the different kinds of objects that were in the data base, and went and demonstrated it at the Second Annual Lunar Science Conference,” which was held in January 1971. “We had it on line for about three days, an hour or two a day, and we had lunar geologists actually coming up, trying it out, and seeing how it worked.”
The geologists had not been told to use any particular format or phrasing-just to ask questions as though conversing with a colleague: “What is the average concentration of iron in Ilmenite?” “Give me references on sector zoning.” The program could even handle questions like, “Give me the modal analyses of those samples for all phases,” realizing that “those samples” referred to information from a previous question.
Of a total of 111 requests, Lunar understood about 90 percent (counting 12 percent which failed because of trivial bugs in the program that were quickly corrected.) The statistics sound impressive, but as Woods wrote, they must be taken “with several grains of salt.” The program worked fine when it was asked questions by geologists, who instinctively knew the kind of information that was likely to be in a geographical data base. But when a graduate student in psychology tried it out he had to ask five questions before he found out that Lunar could understand. “What is the average weight of all your samples?” he asked. Had it been equipped with eyes, Lunar might have blinked stupidly. For one thing “all your” was a construction that its grammar didn’t yet know. Thus the question would not parse. Even if it had been able to analyze the sentence the program would not have understood it. It didn’t contain information on weights in its data base. And, more importantly, it had not been programmed with primitives referring to possession. “Your samples” was a concept that would not compute. Lunar didn’t consider the collection of moon rocks to be something that it owned.
©1985 George Johnson
George Johnson, a freelance writer, is reporting on the quest to build computers smarter than humans.